
Digivaalit-projektimme starttasi alkuvuodesta 2015 tarkoituksenaan tutkia valtasuhteita ja agendaan vaikuttamista eduskuntavaaleissa 2015. Tätä tarkoitusta varten pistimme pystyyn melko mittavan seurantakoneiston ja tallensimme ison aineiston vaaleihin liittyviä julkisia verkkosisältöjä eri sosiaalisen median palveluista sekä perinteisen median sivuilta. Mukana ovat lopulta kansanedustajaehdokkaidet kaikki twiitit ja julkiset Facebook-päivitykset, iso aineisto kansalaiskeskustelua vaaleihin liittyivllä hashtageilla (esim. #vaalit2015, #politiikka), sekä uutisaggregaatin avulla kerätty kaikki politiikka-kategoriaan merkityt uutiset.
Julkaisimme Rajapinnassa jo vaalipäivänä joitakin ensimmäisiä analyyseja enemmänkin kuriositeettimielessä ja yleistä mielenkiintoa ajatellen. Varsinainen datan käsittely ja analyysi kuitenkin pääsi käyntiin vasta vaalien jälkeen.
Ensimmäisenä hankkeen tulosjulkaisuna esittelimme Nordmedia 2015 -konferenssissa Kööpenhaminassa paperin, jossa tutkimme ehdokkaiden vaikutusvaltaa agendaan. Tätä varten rakensimme
Indeksin laskemista varten käytimme neljää eri aineistoa aikarajauksella kaksi kuukautta ennen vaaleja:
- Ehdokkaiden julkiset päivitykset a) Twitteristä ja b) Facebookista (yhteensä 167 395 päivitystä 1128 ehdokkaalta)
- Uutismedian politiikka-uutiset (5427 uutista 19 eri median sivuilta)
- Kansalaiskeskustelut sosiaalisessa mediassa hashtageilla #vaalit2015 #vaalit #politiikka, aineistosta poistettiin ehdokkaiden viestit (80 456 päivitystä)
Suomi kontekstina aiheuttaa omat haasteensa laskennalliselle yhteiskuntatieteelle. Jotta suomenkielistä aineistoa voidaan laskennallisesti käsitellä, täytyy sitä ensin siistiä ja käsitellä. Lukuisten sijamuotojemme vuoksi tärkein toimenpide on lemmatisointi eli sanojen perusmuotoistaminen. Tämä tehdään käytännössä kielitieteilijöiden kehittämällä ohjelmalla, joka on saatavilla suoraan muun muassa CSC:n palvelimilla. Lopputuloksena aineisto muuttuu tämän näköiseksi (esimerkkinä twiitti):
vaali jälkeen olla aloittaa epävirallinen hallitustunnustelut ja keskustella myös työmarkkinaosapuoli sekä etujärjestö kanssa
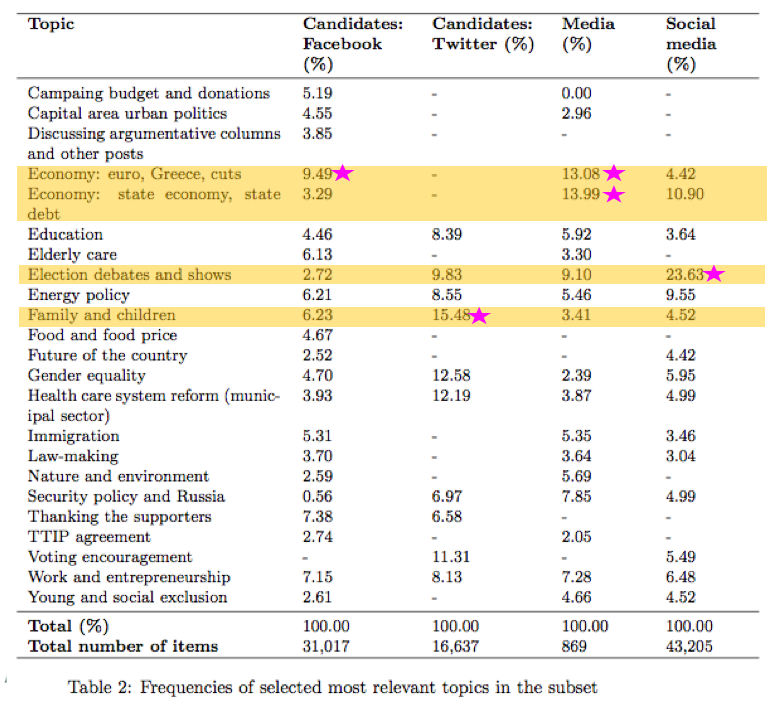
Seuraavaksi kaikki eri aineistot ajettiin topic modelling -skriptin läpi. Topic modelling voitaisiin suomentaa automaattiseksi teemojen mallintamiseksi; käytännössä menetelmä tilastollisesti vertaa tiettyjen sanojen todennäköisyyttä esiintyä lähekkäin ja sen perusteella laskee koko aineistolle mallin, jolla erotetaan teemat toisistaan. Mallintamisen pohjalta saimme eroteltua kullekin aineistolle 32-200 teemaa — eniten teemoja perinteisen median aineistossa. Kartoitimme seuraavaksi selkeimmät teemat yhteen eri aineistojen välillä, jotta pystyimme vertaamaan niitä keskenään. Alla olevassa taulukossa näkyvät aineiston keskeisimpien ja kattavimpien teemojen suhteelliset osuudet eri aineistoissa.
Varsinaisessa analyysissa keskityimme mediassa tai sosiaalisessa mediassa esiintyviin teemapiikkeihin, eli hetkiin, jolloin tiestystä teemasta syntyy yhtäkkiä paljon keskustelua tai uutisia (käytännössä kun teeman esiintymismäärä vähintään kahden keskihajonnan verran korkeampi kuin teeman keskimääräinen esiintymisfrekvenssi). Piikkeihin keskittyminen on sikäli järkevää, että niiden kohdalla vaikuttamisen tunnistaminen on hiukan suoraviivaisempaa: muuten kyseessä voi olla teema, joka jatkuu mediassa päivästä toiseen ja ehdokkaatkin käyvät siitä jatkuvaa keskustelua. Tällaisesta jatkuvasta porinasta on vaikea selkeästi tunnistaa vaikuttajuutta. Joskin täytynee todeta, ettei se piikkien kohdallakaan ole kovin yksiselitteistä.
Seuraavaksi aineiston läpi ajettiin analyysiskripti, joka osoittii ehdokkaalle aina yhden vaikuttajapisteen kun hän tietyssä aikaikkunassa ennen mediassa tai verkkokeskustelussa tunnistettua teemapiikkiä päivittää kyseisestä teemasta.
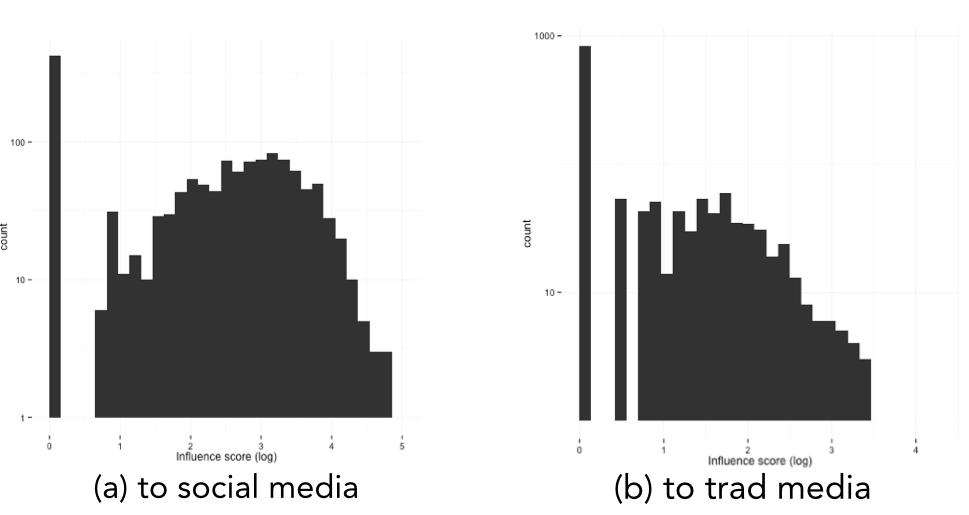
Summaten: näin iso tekstimassakin tiivistyy siistin regressioon! Joskin tämä on selkeästi vasta ensimmäinen koeponnistus: seuraavaksi jonossa on lukuisia eri parannusehdotuksia ja lisätestejä, jota mallissa pitäisi huomioida. Esimerkiksi sosiaalisen median aktiivisuuden roolia tulisi kriittisesti tarkastella ja koettaa pienentää sen efektiä. Lisäksi mallia ja tuloksia voisi koettaa tarkemmin kontekstualisoida näiden vaalien kontekstiin ja tarkastella esimerkiksi sitä, muuttuvatko tulokset jos aineistosta tilapäisesti poistetaan keskeisimmät oppositiojohtajat tai esimerkiksi edellisen hallituksen ministerit. Näillä harjoituksilla kohti lokakuuta!
Teksti pohjautuu paperiin: Nelimarkka, M.; Laaksonen, S-M.; Marttila, M., Kekkonen, A.; Tuokko, M. & Villi, M. (2015). Online agenda building and normalization in Finnish 2015 Parliamentary Election. Paper presented in Nordmedia 2015, Copenhagen, August 2015.
