

Building and Applying Resources for Computational Approaches to Emotion Detection for English and Beyond
MA Emily Öhman’s doctoral dissertation, The Language of Emotions: Building and Applying Resources for Computational Approaches to Emotion Detection for English and Beyond, was publicly examined on March 5, 2021 at the University of Helsinki Faculty of Arts. This is a blog-friendly modification of the lectio praecursoria.
Emotions have always been central to the human experience: the ancient Greeks had philosophical debates about the nature of emotions and Charles Darwin can be said to have founded the modern theories of emotions with his study The expression of the emotions in man and animals. Theories of emotion are still actively researched in many different fields from psychology, cognitive science, and anthropology to computer science.
Sentiment analysis usually refers to the use of computational tools to identify and extract sentiments and emotions from various modalities. In my dissertation I use sentiment analysis in conjunction with natural language processing to identify, quantify, and classify emotions in text.
Specifically, emotions are examined in multilingual settings using multidimensional models of emotions.
One such model is Plutchik’s wheel of emotions. The wheel and related emotional intensities are used to classify emotions in parallel corpora via both lexical methods and supervised machine learning methods. The core emotions are joy, trust, fear, surprise, sadness, disgust, anger, and anticipation with the more intense versions of these core emotions towards the center of the wheel and the less intense towards the tips.

In this dissertation I have developed new approaches to create a more equitable natural language processing approach for sentiment analysis, meaning the development and evaluation of massively multilingual annotated datasets, contributing to the provision of tools for under-resourced languages.
I compare lexicon-based methods and the creation of emotion and sentiment lexicons, the creation of datasets for supervised machine learning, the training of models for supervised machine learning, and the evaluation of such models. I also examine the annotation process in relation to creating datasets in depth, including the creation of a light-weight easily deployed annotation platform. As an additional step, I test the different approaches in downstream applications.
These practical applications include the study of political party rhetoric from the perspective of emotion words used and the intensities of those emotions words. I also examine how simple lexicon-based methods can be used to make the study of affect in literature work in conjunction with computational methods to provide a different perspective. Additionally, I attempt to link sentiment analysis with hate speech detection and offensive speech target identification.
The main contribution of this dissertation is in providing tools for sentiment analysis and in demonstrating how these tools can be augmented for use in a wide variety of languages and practical applications at low cost. In particular I compare machine learning with lexicon-based methods.
The studies that this dissertation consists of examine different methods to extract emotions from text. Beyond sentiment analysis and emotion detection in downstream applications, the studies provide annotation tools, emotion lexicons, and multi-lingual datasets annotated for emotions.
The questions I wanted to answer are:
- What are the advantages and disadvantages of different sentiment analysis and emotion detection methods and how can these be improved upon?
- How well are sentiments and emotions preserved in translation?
- Is cross-lingual sentiment analysis robust enough to be useful for improving sentiment analysis datasets for low-resource languages? Is annotation projection a feasible and reliable method to create datasets for low-resource languages?
- How well do models beyond positive-negative fare in real-world tasks?
Resources used in the dissertation
The SELF & FEIL lexicons
I created the SELF and FEIL lexicons (Sentiment and Emotion Lexicon for Finnish and Finnish Emotion Intensity Lexicon) as a curated Finnish version of the NRC Emotion Lexicon, which has been used in numerous sentiment analysis projects, including some of mine. This lexicon was originally created for English, but then translated to over a hundred other languages using Google Translate. I wanted to improve on these translations for Finnish to be able to do lexicon-based sentiment analysis for Finnish.

Google Translate chooses the most common translation, which isn’t so bad when you are translating sentences and Google Translate has some context, however, when you are translating just one word at a time, this becomes problematic. This table illustrates one of the most common types of corrections made in the lexicon. Here these four different but near-synonymous English words had been all translated into the same Finnish word because that is the most common translation for all of them. If I had kept just that one word the lexicon would have shrunk by 3 words. Therefore instead, synonym dictionaries combined with language knowledge and an understanding of the lexicon’s setup were used to optimize the lexicon for Finnish.
| Original English | Google Translate | Corrected Form(s) |
| birch | koivu | piiskata |
| emaciated | laihtunut (having lost weight) | riutunut |
| rabble | lauma (herd,flock) | roskaväki |
| corroborate | vahvistaa | -entry removed- |
| strengthen | -entry kept- | |
| cede | luovuttaa (to give up) | -entry kept |
| relinquish | -entry removed- | |
| rape | raiskaus (N) | -entry kept- |
| raiskata (V) | -entry added- |
When the lexicon was originally compiled, the annotators were given tests to check that they understood what the word meant. This was not available to Google Translate. Therefore a word like “birch”, which would make most people think of a tree first, is translated by Google as “koivu” – birch tree, when the actual meaning in the lexicon was the act of flogging. Emaciated is a great example of overgeneralization, as it does of course mean to have lost weight but with much more dramatic connotations.
Emotions in Translation
I wanted to create an emotion annotated dataset using projected annotations. What this means is that I would use a parallel corpus of movie subtitles, annotate one language, and then assume that the corresponding subtitle in other languages would contain the same emotion. For this to be feasible I needed to know how well emotions are preserved in translation.
Together with Kaisla Kajava we examined how these emotions are preserved and discovered that for English to Finnish and English to French, JOY was the best preserved emotion. This might be because it is the only unequivocally positive emotion in Plutchik’s core emotions. But for Italian, although JOY was well preserved, SADNESS was the best preserved emotion. For all languages SURPRISE was the least preserved emotion. This was expected as surprise is rarely expressed in text by words and is the most context-dependent of these emotions. Overall, the emotions were preserved quite well.
Sentimentator
Labelling, or annotation, is necessary for supervised machine learning tasks but can quickly become expensive as manual human labor is required. Furthermore, emotion annotation is a particularly difficult task even for trained humans as it is very subjective and many minor things can influence an annotator’s judgement of a sentence’s polarity or the emotions it contains. For this reason annotator agreement is measured to ensure that there is a certain minimum level of agreement for each annotation.
For this reason we created the Sentimentator annotation platform. Out of the box it is available for 8 languages, including Finnish and Swedish. The default data is subtitles from the OpenSubtitles 2018 parallel corpus. Both Sentiment and Emotion annotation is possible, as well as intensity annotation. The platform is also lightly gamified. The annotation scheme used is based on Plutchik’s wheel.
The XED datasets were created using Sentimentator. There are 30 thousand manually annotated English subtitles and 20 thousand Finnish. In addition we have projected annotations for over 40 languages and for 30 of those there are more than 1,000 subtitles for each language and for 12 languages there are more than 10k subtitles. The dataset and BERT based model is available on GitHub.
Applications
Armed with lexicons, datasets, and the assurance of feasibility. I wanted to test these datasets on practical downstream applications.
Computational Literary Studies
I wanted to explore the lexicons I had created from many different angles so I used them to explore Finnish literature from the late 1800s. The following examples are all from the novel Rautatie by Juhani Aho.
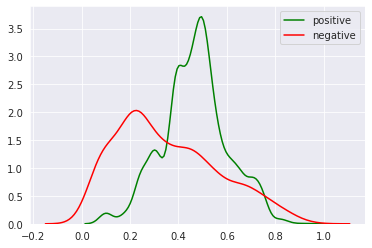
Here you can see the distribution of these sentiments in a KDE plot with green representing positive sentiments and red negative, with intensity on the x axis. As you can see positive words are typically of mid-intensity, with negative words typically less intense.
In literature studies, Russian formalism to be specific, there are two concepts ‘syuzhet’ and fabula that are used when describing narrative construction. Fabula is the chronological order of events in a text, and syuzhet is the way the story is organized. If the narrative in a novel is chronologically linear, the syuzhet and fabula are roughly the same.
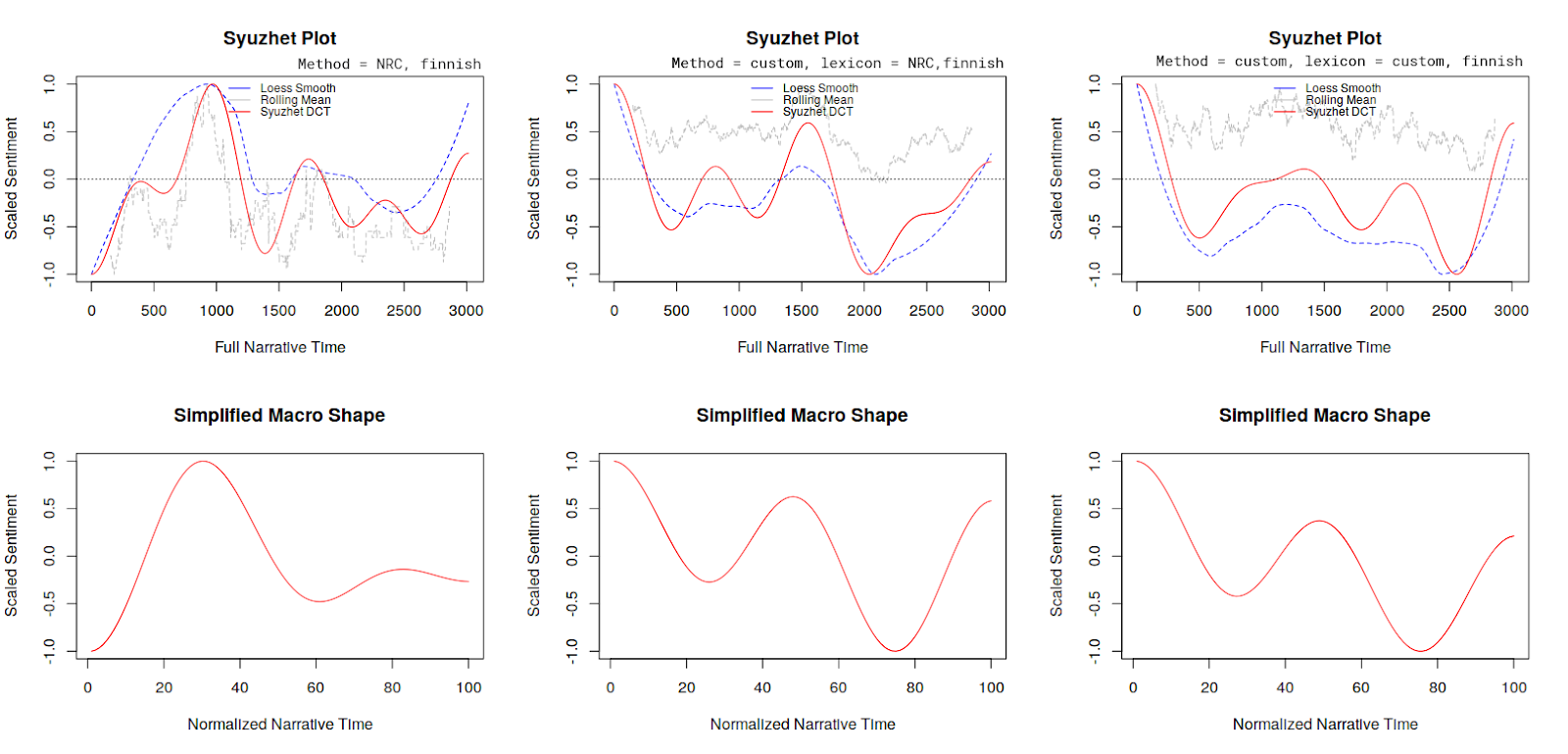
Together with Riikka Rossi, I measured the sentiments in Juhani Aho’s Rautatie using syuzhet. The effects of my lexicon on the automatic analysis of syuzhet in Juhani Aho’s Rautatie can be seen in these graphs. On the left the program is run using the default settings, in the middle the Google translated NRC lexicon, and on the right using my improved version. The simplified macro shape is quite similar for the latter two, however, the more detailed plot shows that there are some noticeable differences between those two analyses, with less positive sentiments in the middle of the novel, in line with an expert analysis of the novel.
Offensive Speech Detection
As for offensive speech detection, in conjunction with our submission to OffensEval 2020, we looked at the emotion word content of offensive and non-offensive social media messages in Danish.
| Jeg har altid mere set dem som en bizar hemipenis, hvor Finland er de sande nosser. | Reddit Comments r/Danmag | OFF | TIN | ORG |
| @USER hvor meget sælger du dig selv for? | Facebook – Extra Bladet | NOT |
The message marked as non offensive could be considered offensive, however, according to the strict annotation scheme of the creators it is not here deemed an offensive message. It should also be noted that simply containing swear words was not sufficient to have a message labeled as offensive.

The top row of the table here shows the sentiment or emotion, the second and third rows show the normalized per 10000 words rate of each emotion word type in non-offensive and offensive messages respectively. As you can see, offensive messages contained far more emotion words than non-offensive messages, and although the difference is most noticeable with negative words, it holds true for positive emotions too including joy.
Political Rhetoric
I also looked at political rhetoric by examining Finnish political party manifestos from 1945 til today together with Juha Koljonen, Pertti Ahonen, and Mikko Mattila.
We discovered, for example, that although populist parties use the same proportional amount of emotion words as other parties do, the intensity of the emotion words they use is significantly higher. In practice this means that where a non-populist party would use a word like “anger”, a populist party would use the word “rage”.
Conclusions
The advantages of lexicon-based methods compared to machine learning is the cost, however, there is a noticeable drop in accuracy. Emotions and sentiments are preserved in translation differently for different language pairs and different emotions are preserved to varying degrees. However, in general emotions seem to be rather well preserved.
As emotions are decently preserved in translation, annotation projection also resulted in reliable annotations for parallel emotion datasets. And finally, the downstream applications using emotion detection, provided some very interesting insights into the language of emotions, particularly political rhetoric, literary analysis, as well as some pilot studies into offensive-speech detection.
Cover image “Color picture” by @Doug88888 is licensed under CC BY-NC-SA 2.0
