
The availability of large data sets and digital material is changing the landscape of research within social sciences and humanities. At the same time, tools and the understanding necessary to utilize such data are often lacking. To tackle this problem, during the last weekend of May we organized a Data Science hackathon around a newly opened data set of Suomi24, the largest online discussion forum in Finland with 1.9 million monthly visitors.
The hackathon was organized by the Citizen Mindscapes research collective, University of Helsinki, Futurice Oy and Aller Media Oy. The event was also part of Nordic Open Data Week and organized in cooperation with Open Knowledge Foundation. The main goal of the event was to allow researchers and coders work together and find new ways of collaborating in the field of data science. We built four different teams consisting of coders and researchers to figure out research problems and create solutions and demos to find their answers.
The dataset used in the event was the almost entire database of Suomi24 online forum discussions ranging from 2001 to 2015, consisting of hundreds of thousands of posts and altogether over 123 million words – a set of data rather impossible to study comprehensively using traditional methods from social science or humanities. Below is a summary of the work and results discovered by the teams.
Rhythms of Human Life in Suomi24
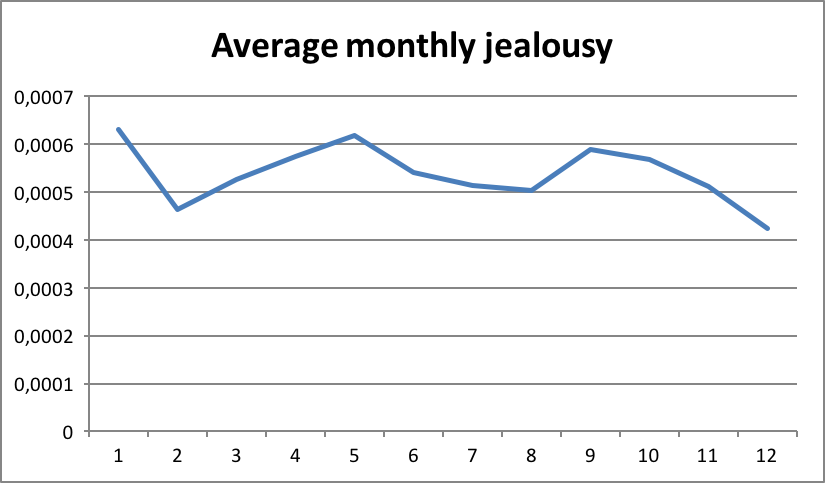
This team was interested in the life cycle of topics in Suomi24. A typical way of studying topics is creating a list of words and querying the data with the words. As one exercise this team tracked the conversations related to jealousy using a list of fifteen related words. They noted that in general the talk about jealousy has increased during the time span of the data. Maybe people were not so used to talk about personal issues online but year by year it is getting more common? Further, the analysis shows that jealousy words peak during January and in May; on the contrary in December discussions on the topic are rare. The team hypothesized that this relates to the well-known phenomenon of finding a summer fling, or the aftermath of all the Christmas parties.
User Modeling and Micro Level Interactions
This team focused on tracking down different interaction types, recognizing positive/negative discussions, and finding out what words or linguistic features are predicting longer discussion threads. In essence these questions directly relate to a very practical problem of how to create interaction in the online sphere and produce text so that the writer can create engagement. The team decided to simply measure this using the length of the thread as the dependent variable, and using MDL (Minimum Description Length) started searching for the linguistic features that are typical to long or short conversation threads. Limiting the analysis to conversation sections related to babies and society, they identified some discreet words, topics and features of the text that are typical for short and long threads (see table below).
| SHORT | LONG |
| – baby section: inconvenient topics (pregnancy, test, symptoms, miscarriage, periods) – society section: god, work, human |
– baby section: boy, kid, man, girl, mother, movie – society section: Jesus, forest, baptize |
| asking, short sentences, question mark, words indicating uncertainty (mikä mutta vai jos), colloquialism | subordinate clauses, certain conjunctions (että, vaikka, ja), quotations, commas |
Forecasting the Economy
Our forecasting team decided to study what words and topics get accentuated during a financial downturn, and to check whether the online discussions could be used as a tool to predict the economical situation. The theoretical idea behind this question comes from John Maynard Keynes’s notion of animal spirits; the instincts, fears and emotions ostensibly influence and guide human behavior, and through that also affect the economic cycle. In order to answer their questions the team obtained additional data sets regarding Finnish GDP and private household consumption from the National Statistics Finland. An index to measure economic uncertainty in the discussions by a set of key words was created using previous studies as a source. An OLS regression model was tested but didn’t have large explanatory power with this data set. Nevertheless, in the next part of the analysis the team identified the words whose frequencies rose during the months of the crisis years 2008 and 2009. So, if the economical situation is going down, what are the words people use more often? The identified words were: bar, mother-in-law, poem, weapon, bank, electricity, unemployed, lonely, Easter, girlfriend. We do hope these words are not related to a single story!
Cats versus Dogs
Our last team decided to solve the old Internet dilemma of cats versus dogs once and for all. It is well known that Internet belongs to cats. But how about Suomi24? Are cats also the most prominent animals there? Different statistics were extracted from the data, but the situation kept looking bad for cats: dogs are mentioned more often across the data. Also the amount of users who talk about dogs versus cats is larger. A final analysis was conducted to see whether other topics that cat/dog persons talk about actually differ. The results show what cat people do talk more about mathematics, where as dog persons talk about poop. This whole exercise of course was just a humorous example of what to do with the data, and how to twist the data so that a needed answer can be found – it is just a matter of what to measure. A critical point to note is thus that one should be cautious of different black boxes of data analytics: there might have been other statistics behind the ones that you are shown.

Some afterthoughts
Apart from the fantastic results from the demos the whole event of course was a learning experience. Most important observation is the need for multidisciplinary knowledge and skills within the teams. Without a more general, wider knowledge about the societal phenomena that are affecting the creation of such social big data in the first place it is not possible to draw relevant conclusions. Our hypotheses of the jealousy discussion, for instance, are pure speculations for now, but probably a dwell into social psychology research on the topics would take us lot further.
Also there’s a clear need to better understand the context of the words studied, as their meaning can be heavily dependent on that. Based on the cat vs. dogs analysis, for instance, we can’t say whether the discussions about cats or dogs are actually pro-cats or pro-dogs or are people actually just complaining about the neighbors pet – this would need deeper analysis regarding the context and tone of the messages.
And of course during two days you probably will not learn that many new skills but rather utilize the old ones in a new context. So no two-day magic crash courses to python coding actually happened, but hopefully some broadening of mindscapes for researches both in social and computational sciences!
- The Suomi24 data set can be explored through FinCLARIN’s Kielipankki Korp-interface. Full data set is available for download for research purposes.
- Follow Citizen Mindscapes researcher collective in Twitter.
- Team members: Rhythms team Pasi Karhu, Limae Phuah, Omar El-Bagawy, Jaakko Suominen, Krista Lagus, Minna Ruckenstein; User Modeling team Antti Rauhala, Krista Lagus; Forecasting team Kimmo Nevanlinna, Timo Nikkilä, Joonas Tuhkuri; Cat vs. Dogs group Matti Nelimarkka, Salla-Maaria Laaksonen.
This post is a cross-posting from Opennorcids.org
